Инструменты Text Mining
Text Mining - алгоритмическое выявление прежде неизвестных связей и корреляций в уже имеющихся текстовых данных.
Технология глубинного анализа текста Text Mining способна выступить в роли "репетитора", который, проштудировав весь курс, преподает лишь наиболее ключевую и значимую информацию. Таким образом, пользователю незачем "просеивать" огромное количество неструктурированной информации. Разработанные на основе статистического и лингвистического анализа, а также искусственного интеллекта технологии Text Mining как раз и предназначены для проведения смыслового анализа, обеспечения навигации и поиска в неструктурированных текстах. Применяя построенные на их основе системы, пользователи смогут получить новую ценную информацию - знания (отсюда).
Далее рассмотрим несколько сервисов и инструментов для работы с текстовой информацией.
uClassify
uClassify - сервер для решения задач классификации - отнесения объекта к заведемо определенным группам или категориям. Работает в виде отдельного сервера (лицензия), или в виде веб-сервиса.
Первая задача, решаемая uClassify - определение языка. Вы можете передать как определенный фрагмент текста, так и url страницы.
Демо: http://www.uclassify.com/browse/uClassify/Text-Language
Например, для текста "This is text to classify" система вернула English в качестве наиболее вероятного ответа:
<?xml version="1.0" encoding="UTF-8" ?> <uclassify xmlns="http://api.uclassify.com/1/ResponseSchema" version="1.00"> <status success="true" statusCode="2000"/> <readCalls> <classify id="cls1"> <classification> <class className="Arabic" p="7.5665e-016"/> <class className="Bulgarian" p="1.09662e-015"/> <class className="Catalan" p="1.13411e-010"/> <class className="Croatian" p="1.66977e-012"/> <class className="Czech" p="6.31433e-010"/> <class className="Danish" p="4.1776e-010"/> <class className="Dutch" p="7.49329e-012"/> <class className="English" p="1"/> <class className="Filipino" p="1.27982e-013"/> <class className="Finnish" p="1.54378e-015"/> <class className="French" p="1.55948e-013"/> <class className="German" p="1.27572e-015"/> <class className="Greek" p="9.55049e-016"/> <class className="Hebrew" p="1.16744e-015"/> <class className="Hungarian" p="3.42417e-010"/> <class className="Indonesian" p="1.18495e-015"/> <class className="Italian" p="8.85129e-016"/> <class className="Korean" p="1.70364e-015"/> <class className="Latvian" p="7.94177e-013"/> <class className="Lithuanian" p="7.77366e-013"/> <class className="Norwegian" p="3.06461e-010"/> <class className="Polish" p="7.43345e-013"/> <class className="Portuguese" p="1.13343e-015"/> <class className="Romanian" p="2.8729e-011"/> <class className="Russian" p="1.32864e-015"/> <class className="Serbian" p="1.28433e-015"/> <class className="Slovak" p="6.22549e-010"/> <class className="Slovenian" p="1.09112e-012"/> <class className="Spanish" p="4.84425e-016"/> <class className="Swedish" p="8.2172e-011"/> <class className="Turkish" p="5.31504e-014"/> <class className="Ukrainian" p="1.25293e-015"/> <class className="Vietnamese" p="3.06328e-014"/> </classification> </classify> </readCalls> </uclassify>
Следующая задача - автоматическая тематическая классификация текстов, т.е. определение, к какой области относится текст.
Демо: http://www.uclassify.com/browse/uClassify/Topics
Пример работы:
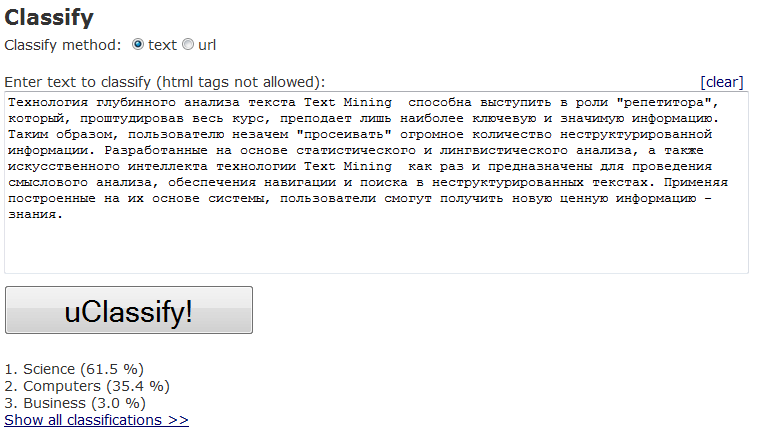
Также есть возможность определения возраста человека, написавшего текст, а также его гендерную принадлженость. Не знаю, как они это делают, но характеристики тех текстов, авторство которых я знаю, они определили правильно.
Еще одной интересной особенностью является определение психического состояния человека по написанному тексту:
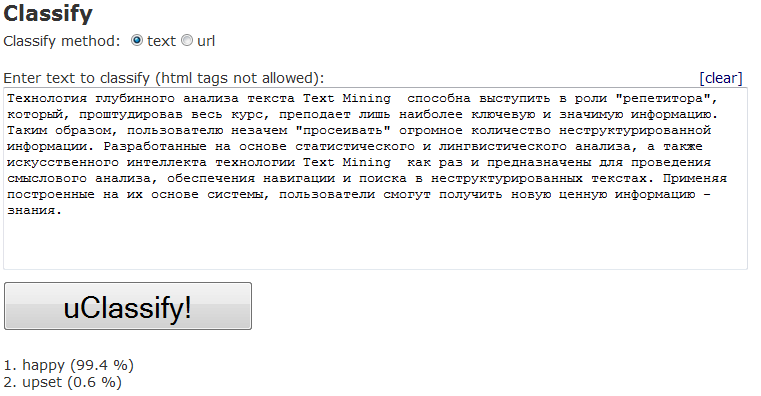
Таким образом, из текста можно сделать вывод, что автор - девушка 13-17 лет, которая была очень счастлива, когда писала этот текст [:)].
Кроме того, сервис позволяет создавать свои классификаторы, а также обучать их.
Java-программисты могут использовать uClassify Java-SDK, остальные - получать данные напрямую из сервиса через API:
using System;
using System.IO;
using System.Net;
namespace example
{
class Program
{
static void Main(string[] args)
{
try
{
// Create the request
string xmlRequest = "REPLACE THIS FOR THE XML REQUEST";
// Send the request
HttpWebRequest webRequest = (HttpWebRequest)WebRequest.Create("http://api.uclassify.com");
webRequest.Method = "Post";
webRequest.ContentType = "text/XML";
StreamWriter writer = new StreamWriter(webRequest.GetRequestStream());
writer.Write(xmlRequest);
writer.Close();
// Read the response
HttpWebResponse webResponse = (HttpWebResponse)webRequest.GetResponse();
StreamReader reader = new StreamReader(webResponse.GetResponseStream());
string xmlResponse = reader.ReadToEnd();
reader.Close();
Console.WriteLine(xmlResponse);
}
catch (Exception e)
{
Console.WriteLine(e.Message);
}
}
}
}
В общем, очень интересный сервис, как по мне, который может использоваться как для исследований, так и для live приложений.
OpenCalais
Еще один интересный сервис, о котором можно говорить очень долго. Если кратко, то OpenCalais - это полноценная Natural Language Recognition система, которая позволяет извлекать сущности, события, факты и связи между ними:

Архитектра OpenCalais:

Живое демо можно посмотреть на http://viewer.opencalais.com/
Пример:
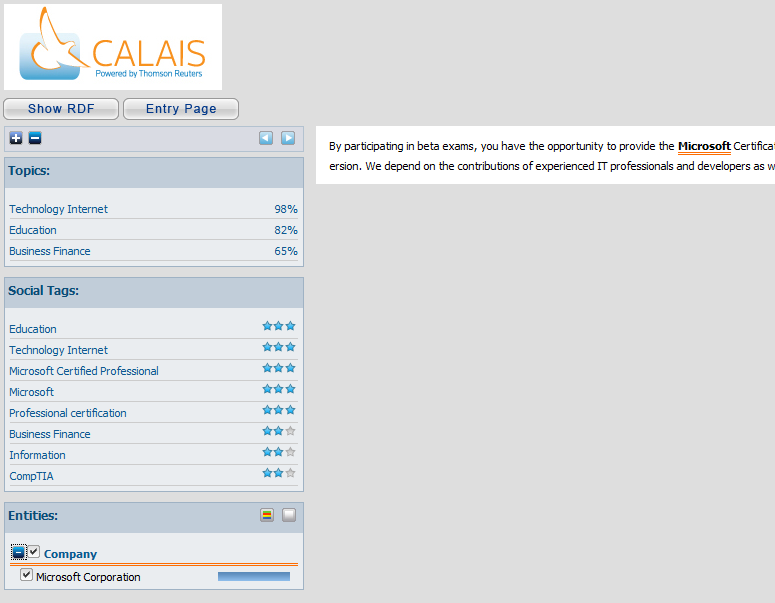
Что же умеет определять OpenCalais:
- Нахождение сущностей, фактов, событий (Entity/Fact/Event Index and Definitions)
- Извлечение связей (Generic Relation Extraction)
- Оценка релевантности сущностей (Entity Relevance Score)
- Социальные теги (Social Tags)
- Категоризация документов (Document Categorization)
- Нахождение сущностей с множественными значениями (Entity Disambiguation)
- Работа с Semantic Web
Поддерживается английский, испанский, французский языки. Поставляется в виде веб-сервиса, есть тестовое приложение на C#.
Lucene.NET
Lucene.NET - это портированный с Java фреймворк для полнотекстового поиска. Позволяет создавать свои индексы документов, проводить нормализацию текстов, управлять стоп-словами, синонимами и т.д.
Сайт: http://lucene.apache.org/lucene.net/
Пример окна - Analyzer Viewer:
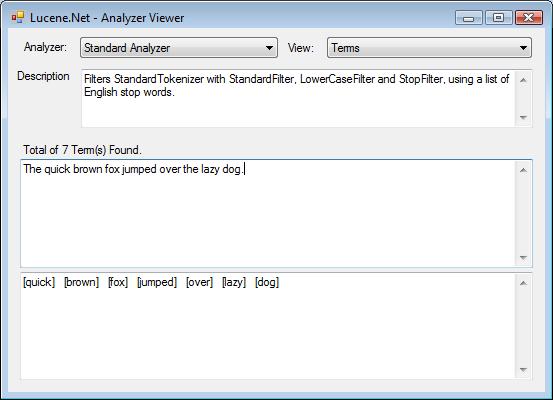
Ссылки по Lucene.NET:
- Introducing Lucene.Net
- Lucene.Net - Text Analysis
- Lucene.Net – Custom Synonym Analyzer
- Working with Lucene.NET
Также при работе с текстами вам, наверняка, придется столкнутся с задачами нормализации текстов, проверки правописания, нахождением синонимом и антонимов, расшифровке аббревиатур и т.д. Если эта тема интересна, то можно на этом остановиться более детально в следующих публикациях. Также, думаю, будет интересно ознакомиться с документом Text Mining Tools on the Internet Overview.