Кластеризация: алгоритмы k-means и c-means
Добрый день!
Сегодня хочу рассказать о двух алгоритмах кластеризации (k-means и
c-means), описать преимущества и недостатки, дать некоторые
рекомендации по их использованию. Итак, поехали…
Кластеризация — это разделение множества входных векторов на группы (кластеры) по степени «схожести» друг на друга.
Кластеризация в Data Mining приобретает ценность тогда, когда она
выступает одним из этапов анализа данных, построения законченного
аналитического решения. Аналитику часто легче выделить группы схожих
объектов, изучить их особенности и построить для каждой группы
отдельную модель, чем создавать одну общую модель для всех данных.
Таким приемом постоянно пользуются в маркетинге, выделяя группы
клиентов, покупателей, товаров и разрабатывая для каждой из них
отдельную стратегию (Википедия).
Меры расстояний
Для того, чтобы сравнивать два объекта, необходимо иметь критерий, на основании которого будет происходить сравнение. Как правило, таким критерием является расстояние между объектами.
Есть множество мер расстояния, рассмотрим несколько из них:
Евклидово расстояние — наиболее распространенное расстояние. Оно является геометрическим расстоянием в многомерном пространстве.
Квадрат евклидова расстояния. Иногда может возникнуть желание
возвести в квадрат стандартное евклидово расстояние, чтобы придать
большие веса более отдаленным друг от друга объектам.
Расстояние городских кварталов (манхэттенское расстояние). Это
расстояние является просто средним разностей по координатам. В
большинстве случаев эта мера расстояния приводит к таким же
результатам, как и для обычного расстояния Евклида. Однако отметим, что
для этой меры влияние отдельных больших разностей (выбросов)
уменьшается (так как они не возводятся в квадрат).
Расстояние Чебышева. Это расстояние может оказаться полезным,
когда желают определить два объекта как «различные», если они
различаются по какой-либо одной координате (каким-либо одним
измерением).
Степенное расстояние. Иногда желают прогрессивно увеличить или
уменьшить вес, относящийся к размерности, для которой соответствующие
объекты сильно отличаются. Это может быть достигнуто с использованием
степенного расстояния.
Выбор расстояния (критерия схожести) лежит полностью на исследователе.
При выборе различных мер результаты кластеризации могут существенно
отличаться.
Алгоритм k-means (k-средних)
Наиболее простой, но в то же время достаточно неточный метод
кластеризации в классической реализации. Он разбивает множество
элементов векторного пространства на заранее известное число кластеров
k. Действие алгоритма таково, что он стремится минимизировать
среднеквадратичное отклонение на точках каждого кластера. Основная идея
заключается в том, что на каждой итерации перевычисляется центр масс
для каждого кластера, полученного на предыдущем шаге, затем векторы
разбиваются на кластеры вновь в соответствии с тем, какой из новых
центров оказался ближе по выбранной метрике. Алгоритм завершается,
когда на какой-то итерации не происходит изменения кластеров.
Проблемы алгоритма k-means:
- необходимо заранее знать количество кластеров. Мной было предложено метод определения количества кластеров, который основывался на нахождении кластеров, распределенных по некоему закону (в моем случае все сводилось к нормальному закону). После этого выполнялся классический алгоритм k-means, который давал более точные результаты.
- алгоритм очень чувствителен к выбору начальных центров кластеров. Классический вариант подразумевает случайный выбор класторов, что очень часто являлось источником погрешности. Как вариант решения, необходимо проводить исследования объекта для более точного определения центров начальных кластеров. В моем случае на начальном этапе предлагается принимать в качестве центов самые отдаленные точки кластеров.
- не справляется с задачей, когда объект принадлежит к разным кластерам в равной степени или не принадлежит ни одному.
Материалы по теме:
- Википедия — K-means
- Introduction to K-means
- Описание функции kmeans в Matlab Statistics Toolbox
- K-means — Interactive demo (Java)
Нечеткий алгоритм кластеризации с-means
С последней проблемой k-means успешно справляется алгоритм с-means.
Вместо однозначного ответа на вопрос к какому кластеру относится
объект, он определяет вероятность того, что объект принадлежит к тому
или иному кластеру. Таким образом, утверждение «объект А принадлежит к
кластеру 1 с вероятностью 90%, к кластеру 2 — 10% » верно и более
удобно.
Классический пример с-means — т.н. «бабочка» (butterfly):
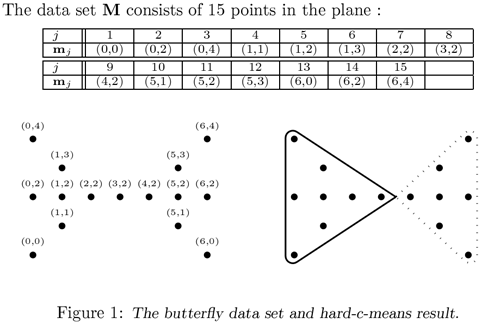
Как видно, точка с координатами (3,2) в равной степени принадлежит как первому так и второму кластеру.
Остальные проблемы у с-means такие же, как у k-means, но они нивелируются благодаря нечеткости разбиения.
Ссылки по теме:
- Формальное описание алгоритма и реализация на C#
- Fuzzy c-means clustering
- Fuzzy C-means cluster analysis
P.S. Я не описывал математические принципы алгоритмов, с ними легко можно ознакомиться по представленным ссылкам.
Спасибо за внимание!