Распределённые вычисления. Qizmt - MySpace’s Open Source Mapreduce Framework
Вступление
Я думаю что не ошибусь если скажу что Qizmt - наиболее доступный фреймворк для распределённого программирования на .net языках. Есть ещё Dryad, но он требует HPC Server и для него пока доступно только preview. Есть также WCF и сокеты, но там всё несколько сложнее. Сдесь же самое интересное это сам MapReduce. Qizmt поддерживает .Net 3.5 SP1 on Windows 2003 Server, Windows 2008 Server, Windows Vista and Windows 7. Лицензия GNU General Public License v3. Цель данной статьи ознакомить Вас с тем что такое MapReduce и Qizmt. На домашней странице проекта есть описание того как этим проектом пользоваться, поэтому в этой статье будут указаны только основы и нюансы.
Введение в MapReduce
MapReduce - это подход к программированию кластеров, в упрощённом виде его объясняет следующая схема (в скобках указаны имена этапов как их называют в Google)
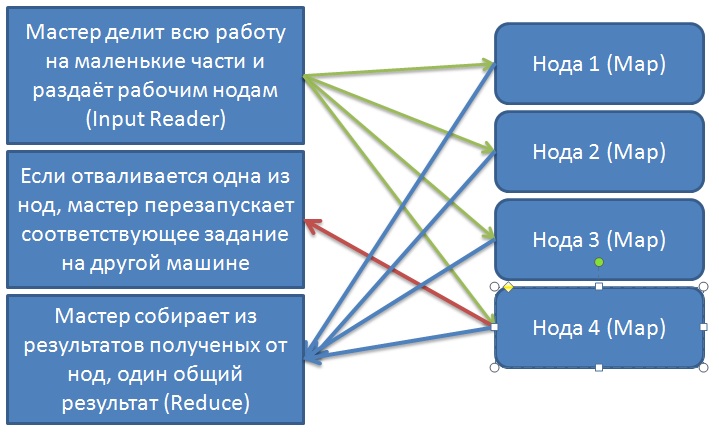 |
Для более матёрых следующая схема :
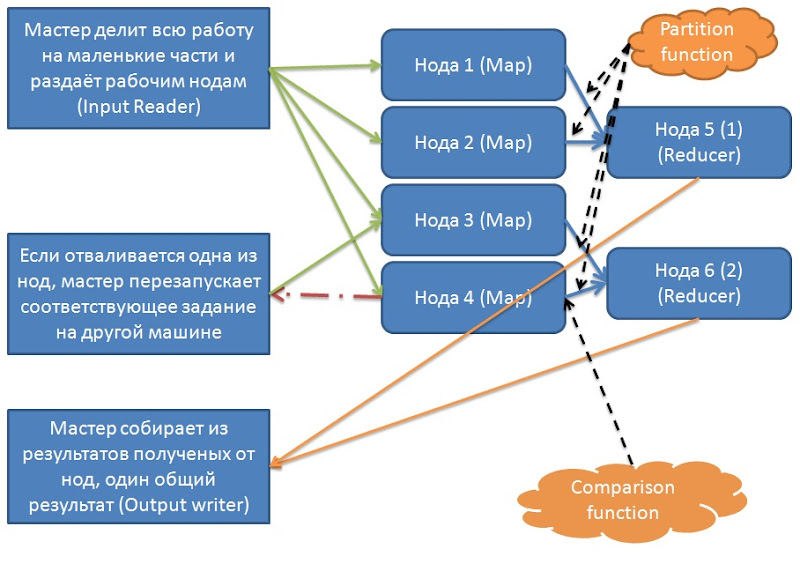 |
Reduce объединяет результаты работы разных машин связанные одним ключом. Возьмём например задачу подсчёта количества каждого слова в тексте :
Делим текст на 10 частей (для 10 нод), каждая нода считает для каждого слова, сколько раз встретилось в тексте это слово - это мап, а потом мы назначаем для каждого конкретного слова свой reducer (непосредственно разделение это partition function, до этого машины обмениваются между собой информацией о том кто какие слова нашёл - это comparison function), каждый reducer суммирует количество вхождений его слова в фрагменты текста, что достались разным машинам (например на 3 машинах из 10 нашлось слово "булка" - на 1-ой 4 раза, на 2-ой - 2 раза, а на 3-ей - аж 20, редьюсер суммирует эти числа, его результат = 4+2+20). В реальной жизни мап и редьюс задач значительно больше узлов в кластере что обеспечивает очень хорошую балансировку нагрузки.
Основное отличие MapReduce от любого другого способа работы с кластером в том что не нужно думать на какой машине будет работать конкретный вызов, не важно какое количество рабочих машин, и не важно что они могут вырубится. Самое основное это то что фреймвор организует эффективное взаимодействие между машинами - а программист пишет программу для одной машины (map), не думая о том как себя будет вести вся система. Возможно, некоторые варианты программирования кластера будут более эффективны для конкретной конфигурации, но производительность MapReduce очень хороша масштабируется при увеличении количества машин и это очень важно. Грубо говоря MapReduce всегда будет работать быстрее на кластере из N+1 машин чем на кластере из N таких же машин. И этим практически обходит закон Амдала.
Почему Qizmt
Эта платформа поддерживает избыточность, масштабируемость и отказоустойчивость. Разработка ведётся на C#, есть среда и отладчик, есть Cluster Assembly Cache (CAC) – кеш .NET assemblies, задачи можно создавать на любой машине в кластере. Также есть 3 вида задач:
— Mapreduce-set логика для больших объемов данных
— Remote – просто удалённые задачи
— Local – оркестрация связей между Mapreduce и Remote jobs
Установка Qizmt
Ниже приведён рисунок с домашней страницы проекта. В принципе всё просто, но я его вставил не просто-так.

В документации этого нигде не написано, но в всплывающем окошке с последнего скрина (справа, снизу), вводится имя и пароль пользователя с домена. Для этого нужно иметь установленный и настроенный Active Directory Domain services. В обоих релизах Windows Server 2008 это делается посредством Server Manager.
Qizmt. Продолжение
Вот так запускаются задачи на исполнение на кластере.

Вот только одна проблема настоящее имя выполняемого файла на диске - zd.QizmtWordC.65657094-9103-41ce-b75d-40542da596ea.zd . Результаты вычислений лежат в файле с именем zd.0.WordCountO.47b811c3-2be8-4a5c-b22f-2f60f1f0cf06.zd , что тоже не очень интуитивно. Для того что бы не запутаться с именами файлов, следует работать с ними только через консольные команды которые предложены в тьюториале.
Если опустить маркап то C# код выглядит вот так
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | public virtual void Map(ByteSlice line, MapOutput output) { mstring sLine= mstring.Prepare(line); mstringarray parts = sLine.SplitM(' '); for(int i=0; i < parts.Length; i++) { mstring word = parts[i]; if(word.Length > 0 && word.Length <= 16) // Word cannot be longer than the KeyLength! { output.Add(word.ToLowerM(), mstring.Prepare(1)); } } } public override void Reduce(ByteSlice key, ByteSliceList values, ReduceOutput output) { mstring sLine = mstring.Prepare(UnpadKey(key)); sLine = sLine.AppendM(',').AppendM(values.Length); output.Add(sLine); } |
Выглядит вполне интуитивно, единственное что смущает это то что у них свой тип сток, начинает С++ напоминать...
Вывод
Программировать кластеры на C# можно и это не так уж страшно )))
Компании из статьи
| Microsoft Украина |