Получение основного контента веб-страниц программно
Задача очищения веб-страниц от информационного шума — это одна из актуальных задач информационного поиска. Суть ее заключается в том, чтобы очистить информационный шум и получить лишь основной контент.
Рассмотрим пример:
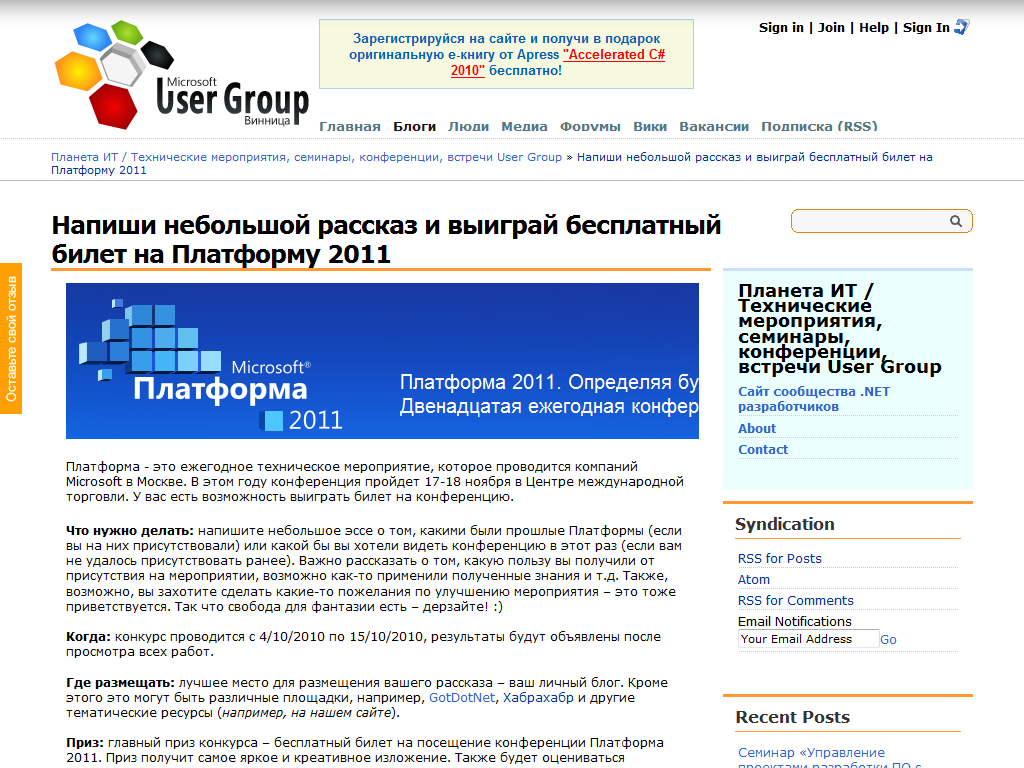
Основным контентом можно считать вот эту часть страницы:
 Где это можно применять:
Где это можно применять:
- сервисы доставки контента, когда другие способы по каким-то причинам не подходят (например, RSS лента отсутствует или выдает только введение);
- системы по сбору некоторой информации из различных источников
- в мобильных приложениях, где важно минимизировать траффик
- системах data mining, BI
Прежде чем приступить к описанию решения, остановлюсь кратко на существующих решениях. С приходом HTML5 проблема находжения основного контента должна исчезнуть, так как по спецификации подразумеваются новые семантические элементы. Рассмотрим их более детально.
Семантические элементы HTML5
В данный момент предполагаются такие семантические элементы:
- section — элемент группирует тематические блоки. Элементы section могут быть вложены друг в друга
- header — содержит в себе заголовок какой либо секции, таблицы и т.д.
- footer — подвал веб-страницы, обычно в этом блоке размещают информацию о сайте, контакты, копирайты
- nav — блок навигации, список ссылок, смежных тем
- article — основной контент
- aside — не основной блок, как правило, находится по бокам страницы
Классическая структура блогозаметки:  Использование этого метода в данный момент сталкивается с такими проблемами:
Использование этого метода в данный момент сталкивается с такими проблемами:
- спецификация HTML5 находится в статусе черновика
- IE на данный момент не поддерживает эти теги
- необходимо, чтобы все разработчики придерживались единых правил разметки веб-страниц
- никто не отменял нечестных SEO оптимизаторов
Но самая большая проблема на данный момент — это наличие миллиардов страниц, которые были написаны очень давно и вряд ли уже будут переписаны с помощью новых стандартов. Именно поэтому задача идентификации основного контента является важной и актуальной.
Readability
Сайт: http://lab.arc90.com/experiments/readability/
Readability — разработка Arc90 Lab, которая позволяет установить небольшой bookmark, который поможет приводить веб-страницы в удобочитаемый вид. Readability использует свои метрики для анализа DOM модели и идентификации «полезного» контента.
Пример использования Readability:  На данный момент есть плагины для различных браузеров, а в Safari эта возможность известна как Safari Reader. Для тех, кто работает в интернете, этого должно быть достаточно, но что делать тем, кто хочет использовать данный инструмент для написания собственных сценариев? Собственно, об этом далее.
На данный момент есть плагины для различных браузеров, а в Safari эта возможность известна как Safari Reader. Для тех, кто работает в интернете, этого должно быть достаточно, но что делать тем, кто хочет использовать данный инструмент для написания собственных сценариев? Собственно, об этом далее.
Исследования проблемы важности информационнных блоков
Ряд моих предыдущих статей были посвящены исследованию этой проблемы, в частности, предлагаю ознакомиться с такими публикациями:
- Очищаем веб-страницы от информационного шума
- Web pages content analysis with SmartBrowser
- Критерий SeoRank для определения основного контента веб-страниц
- Об информационном поиске, нахождении оптимальных путей просмотра результатов поиска и многом другом
Собственная разработка — SmartBrowser — прототип браузера, который очищает веб-страницы от информационного шума, уже долгое время доступен на сайте codeplex по адресу http://smartbrowser.codeplex.com/.
Новая версия SmartBrowser будет скоро доступна на сайте. Процент правильно распознанных веб-страниц увеличился, в то время когда модели и алгоритмы упростились в результате проведенных экспериментов и исследований.
В данный момент SmartBrowser выглядит таким образом:
Вся логика энкапсулирована в классе MainContentExtractor из разработанной библиотеки Data Extracting SDK (в данный момент этой функциональности на сайте еще нет), о которой я уже несколько раз писал.
В итоге я получил следующие результаты для ряда известных сайтов:
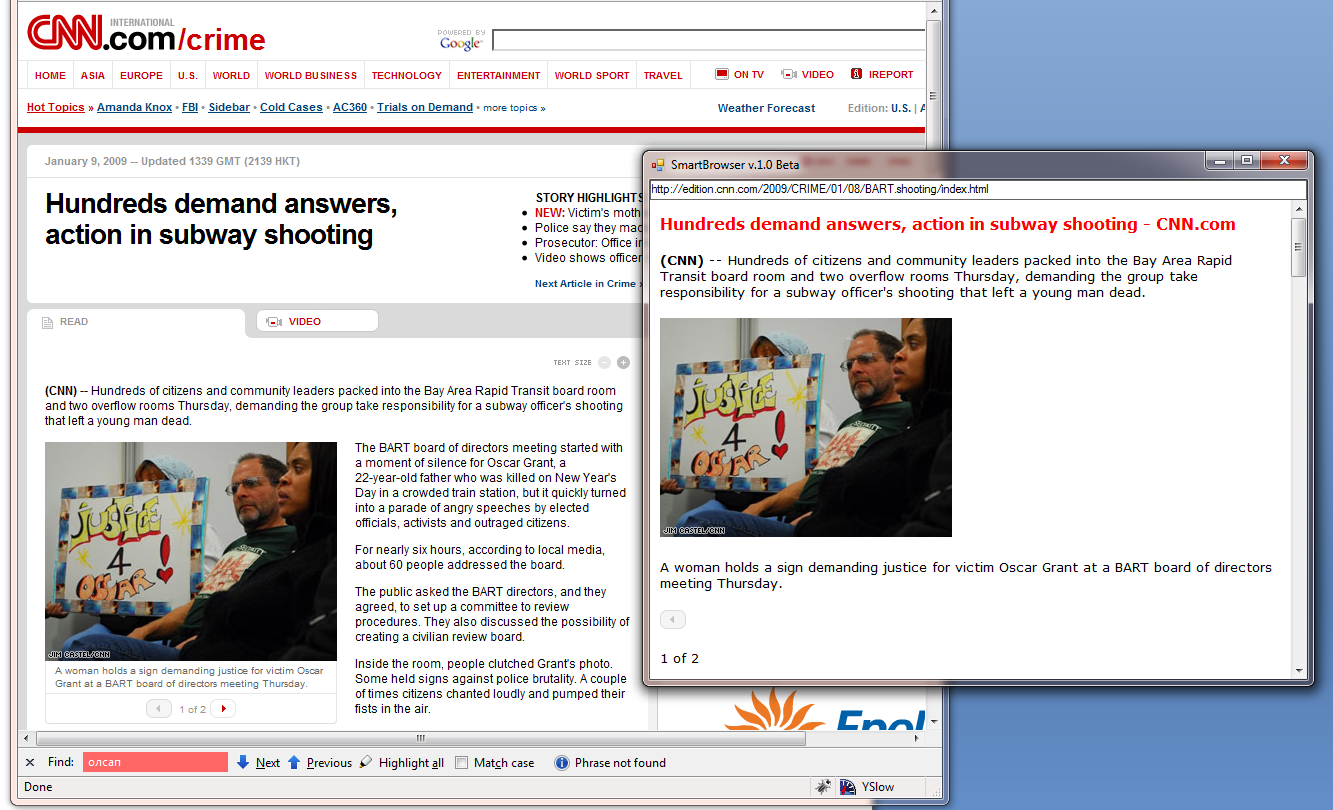
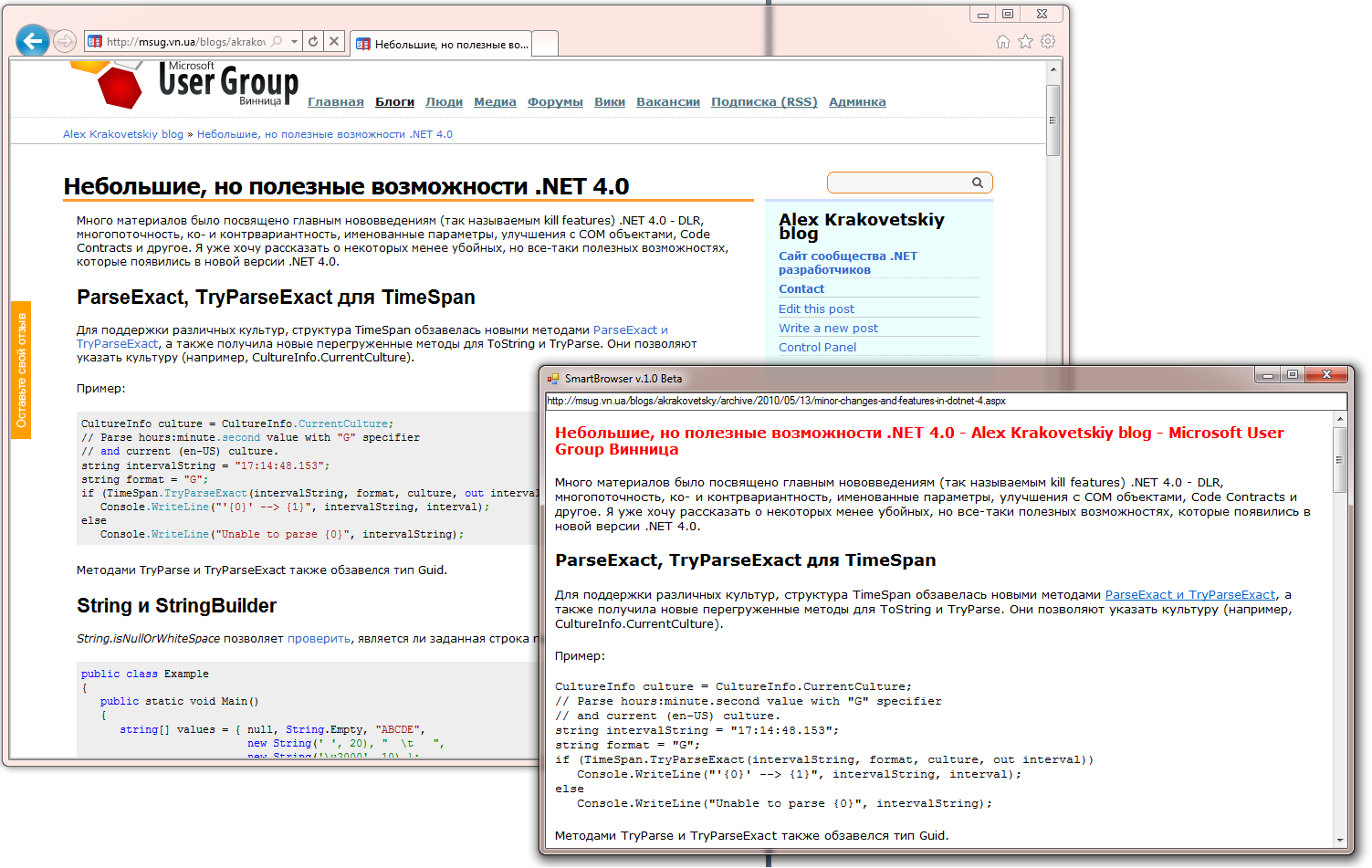
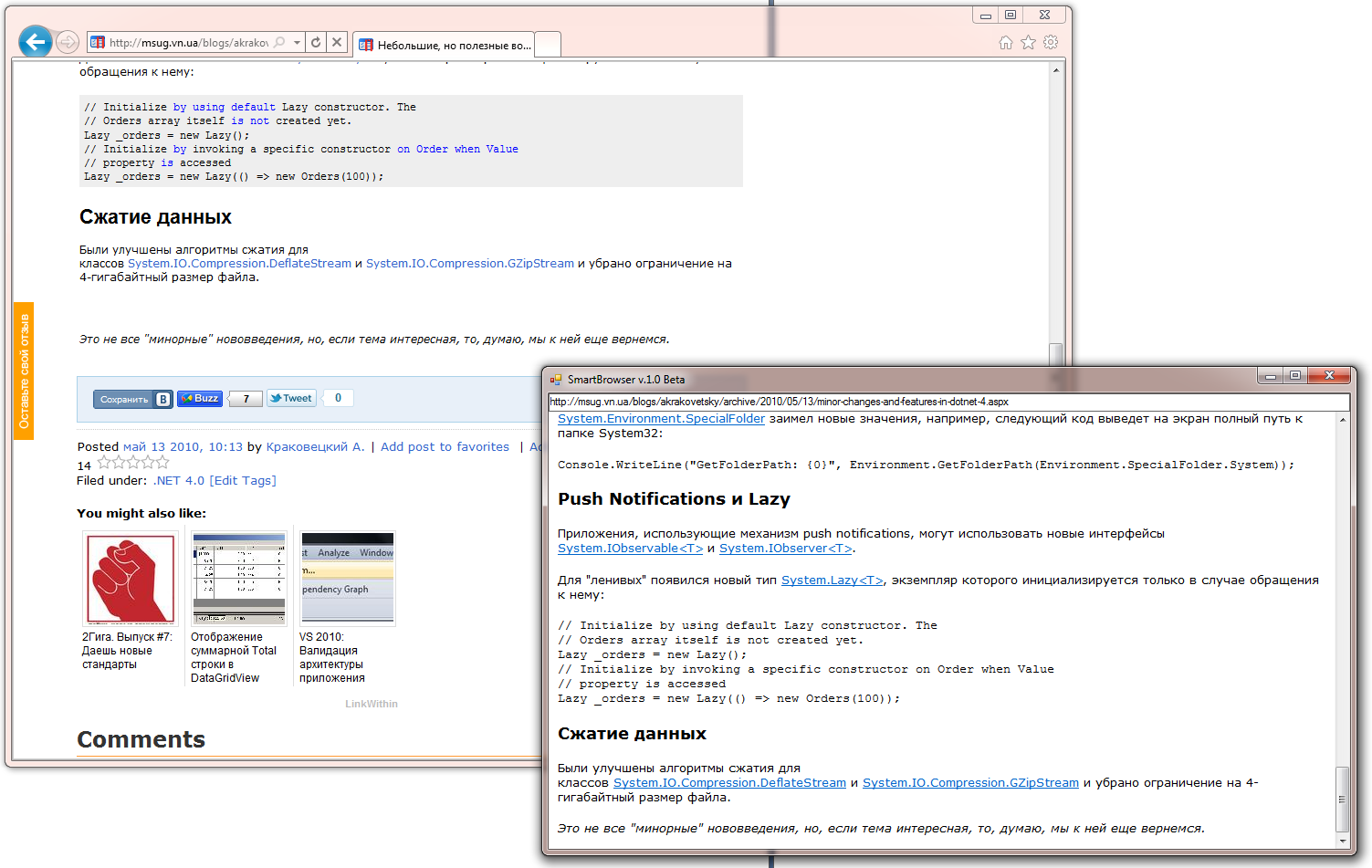

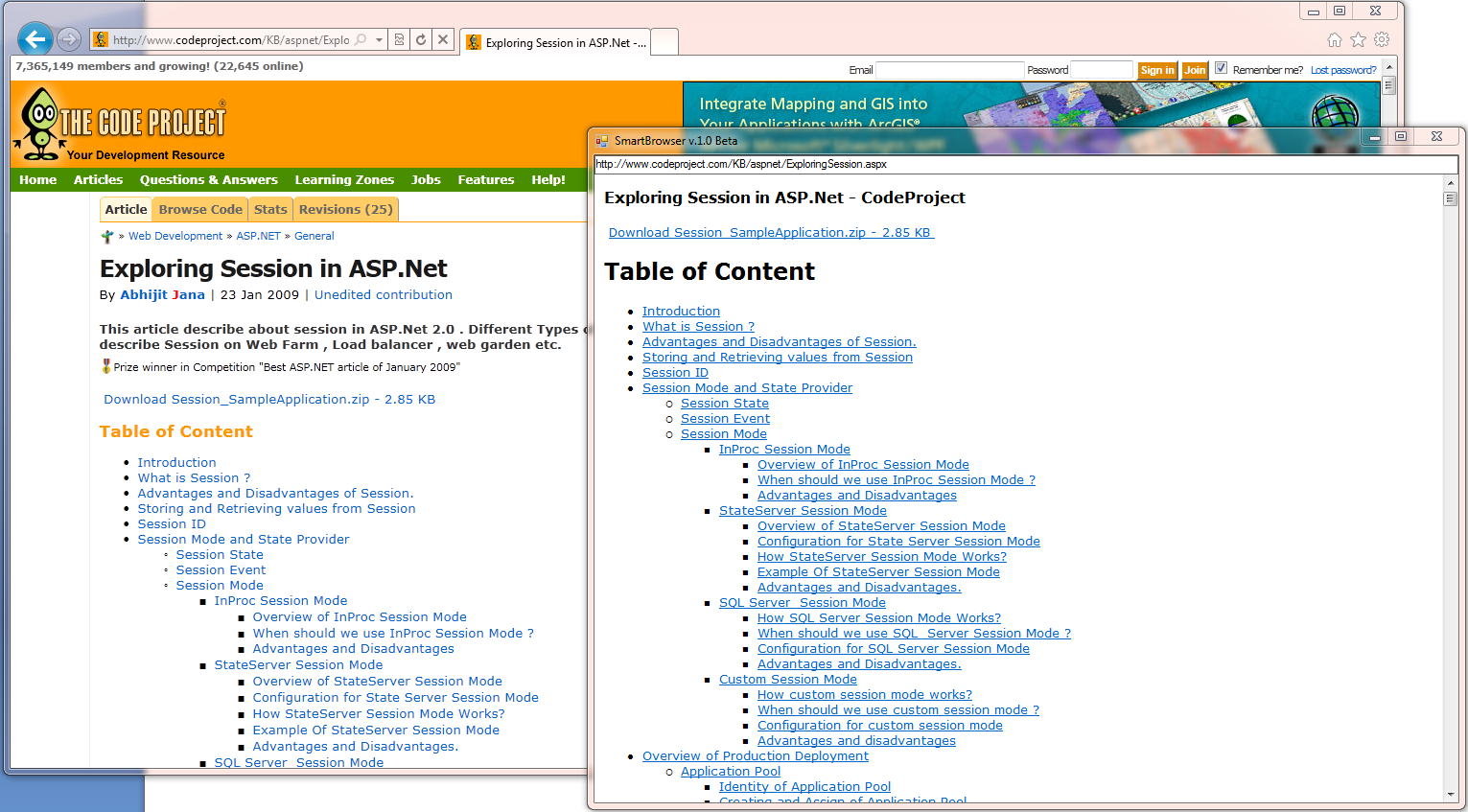

В данный момент есть проблемы с некоторыми сайтами, например, с хабром. Поэтому в данный момент исследования и разработка продолжаются, но, надеюсь, что в ближайшем будущем можно будет говорить о какой-то стабильной сборке.