Семантический HTML5. Часть 1
Когда пользователь заходит на веб-сайт, он видит кросиво оформленные веб-страницы, графику, информационные блоки, стили и легко может определить основной контент от рекламы. Поисковые машины и роботы видят все страницы одинаково – для них это все лишь набор HTML текста. Таким образом, восприятие и обработка информации человеком и машиной отличается. Но когда разработчик сайта делает свой сайт, то, скорее всего, он хочет, чтобы его детище воспринималось всеми одинаково. К сожалению, на практике это выглядит совсем не так.
Для того, чтобы повысить «читаемость» веб-страниц поисковыми роботами и ботами, необходимо каким-то образом добавить «читабельности» своим веб-страницам. Вот тут на сцену и выходит семантика.
Семантика в классическом понимании означает «понимание» чего-либо. Например, для текстов понимание семантики означает понимание смысла написанного.
Чтобы объяснить различия между синтаксическим и семантическим анализами, приведу такой пример: допустим, нам необходимо найти тексты, которые являются дубликатами. Если использовать синтаксический анализ (вместе с морфологическим), то смогут быть найдены лишь тексты, которые содержат одинаковые предложения и различаются лишь немного. Но если над текстами поработал профессиональный копирайте, то найти смысловые дубликаты можно только с помощью семантического анализа. Если первые алгоритмы развиты достаточно хорошо, то другие – не так хорошо, как хотелось бы.
Этот пример я привел для объяснения другого термина – Semantic Web, который обозначает создание единного информационного пространства, где главными единицами информации выступают сущности и онтологии. Концепция Semantic Web подразумевает использование своих стандартов (отличных от привычных HTML и CSS) для описания структуры и смысла ваших страниц. Такие стандарты были разработаны всемирным консорциумом W3C – RDF, OWL, SparQL и т.д. Очень многие сайты начали внедрять API для доступа к своим данным не только в виде HTML, но и RDF, XML, JSON, что требует больших затрат разработчиков, но упрощает жизнь поисковым системам. Очень многие поисковые системы получили звание «семантических» - начиная от Yahoo!, заканчивая Google и Bing, так как они научились искать по ресурсам с RDF разметкой.
Resource Description Framework (RDF) — это разработанная модель для представления данных, в особенности — метаданных. RDF представляет утверждения о ресурсах в виде, пригодном для машинной обработки. RDF является частью концепции семантической паутины.
Semantic Web еще часто называет Web 3.0, но, фактически Web 2.0 и Web 3.0 уже многие годы существуют вместе.

Технологическая карта концепций Веб. Источник: Dal Web3.0 al Web4.0 [36] (полный размер)
{kind=link}
Пример: статья в Википедии о Tony Benn в RDF формате имеет следующий вид:
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:foaf="http://xmlns.com/foaf/0.1/"
xmlns:dc="http://purl.org/dc/elements/1.1/">
<rdf:Description rdf:about="http://en.wikipedia.org/wiki/Tony_Benn">
<dc:title>Tony Benn</dc:title>
<dc:publisher>Wikipedia</dc:publisher>
<foaf:primaryTopic>
<foaf:Person>
<foaf:name>Tony Benn</foaf:name>
</foaf:Person>
</foaf:primaryTopic>
</rdf:Description>
</rdf:RDF>
На самом деле идет небольшая подмена понятий – поисковые системы не научились полностью понимать «смысл» текстов, просто с помощью дополнительной мета информации они могут повысить достоверость идентификации сущностей в слабо структурированных текстах. Соотвественно, без участия человека не обойтись.
Есть целый ряд задач, который призван решить главную задачу – научить роботов «понимать» тексты, среди которых: находжение дубликатов, источников, нахождение сущностей (named entity recognition), автоматический перевод, аннотирование текстов, создание автоматических каталогов, определение основного контента веб-страниц, разбиение веб-страниц на информационные блоки, анализ эмоций, возраста, пола и т.д. Каждая из этих задач сложная и не до конца решенная.
В контексте веба семантика означает «с помощью какого-либо способа сообщить поисковому роботу, какой смысл несет тот или иной информационный блок».
Какие способы решение этой проблемы есть? Давайте рассмотрим их подробней.
Методы внедрения семантических данных
Первый метод, который мы уже рассмотрели – это использование RDF/OWL/XML для описания данных. Такой подход имеет ряд преимуществ.
Преимущества:
- Единое информационное поле и API доступа
- Более удобная индексация поисковыми системами
- Нет привязки к конкретному ресурсу
Но, к сожалению, не лишен недостатков, которые нивелируют ценность такого подхода.
Недостатки:
- Практическая нереализуемость
- Дублирование информации
- Невозможность получения коммерческой выгоды
Самая главная проблема – это практическая нереализуемость, так как заставить всех разработчиков планеты использовать две размеки – HTML и RDF просто нереально. А без этого информационное поле будет неполным. В данный момент есть возможность распарсить только большие ресурсы аля Вики, так как они имеют строгую (и известную) разметк, что позволяет более и менее создать HTML 2 RDF конвертор. Примеры реализации: Wikipedia -> FreeBase и DBPedia. Кроме того, некоторые большие компании также предоставляют свои данные в форамах RDF/JSON/XML, например The New York Times, TechCrunch и другие.
Микроформаты
Еще одним способом рассказать поисковым системам о себе является использование микроформатов (разработка все тех же W3C) . Микроформаты – это рекомендации как верстать свои сайты и подразумевают использование специальных понятных имен CSS классов и идентификаторов.
Пример.
Предположим, что имеется контейнер с уже размеченной информацией о человеке:
<div>
<div>Василий Пупкин</div>
<div>Рога и Копыта</div>
<div>495-564-1234</div>
<a href="http://example.com/">Мой сайт</a>
</div>
С помощью микроформата hCard можно добавить семантическую значимость этому блоку кода:
<div class="vcard">
<div class="fn">Василий Пупкин</div>
<div class="org">Рога и Копыта</div>
<div class="tel">495-564-1234</div>
<a class="url" href="http://example.com/">Мой сайт</a>
</div>
Для человека, который читает веб-страницу, ровным счетом ничего не изменилось, но поисковая система найдет класс vcard и поймет, что речь идет о персональных данных Василия.
Каждый микроформат решает определённую, отдельную задачу. Вот наиболее известные из них:
- hCard — организации и люди;
- hCalendar — события;
- hAtom — ленты новостей (как аналог RSS и Atom) в обычном HTML или XHTML;
- XFN — социальные взаимоотношения;
- rel-tag — метки (теги) и образование фолксономии;
- xFolk — помеченные ссылки;
- adr — почтовые адреса;
- geo — географические координаты (широта и долгота);
- hReview — отзывы (о товарах, услугах, событиях и тому подобном);
- hProduct — товары;
- nofollow — для предотвращения индексации поисковыми системами определённых документов;
- hRecipe — кулинарные рецепты приготовления блюд.
Разработка новых микроформатов продолжается. Среди множества предлагаемых микроформатов наиболее близки к завершению микроформаты для разметки цитат и валют. (Википедия)
Вот шпаргалка по всем микроформатам:
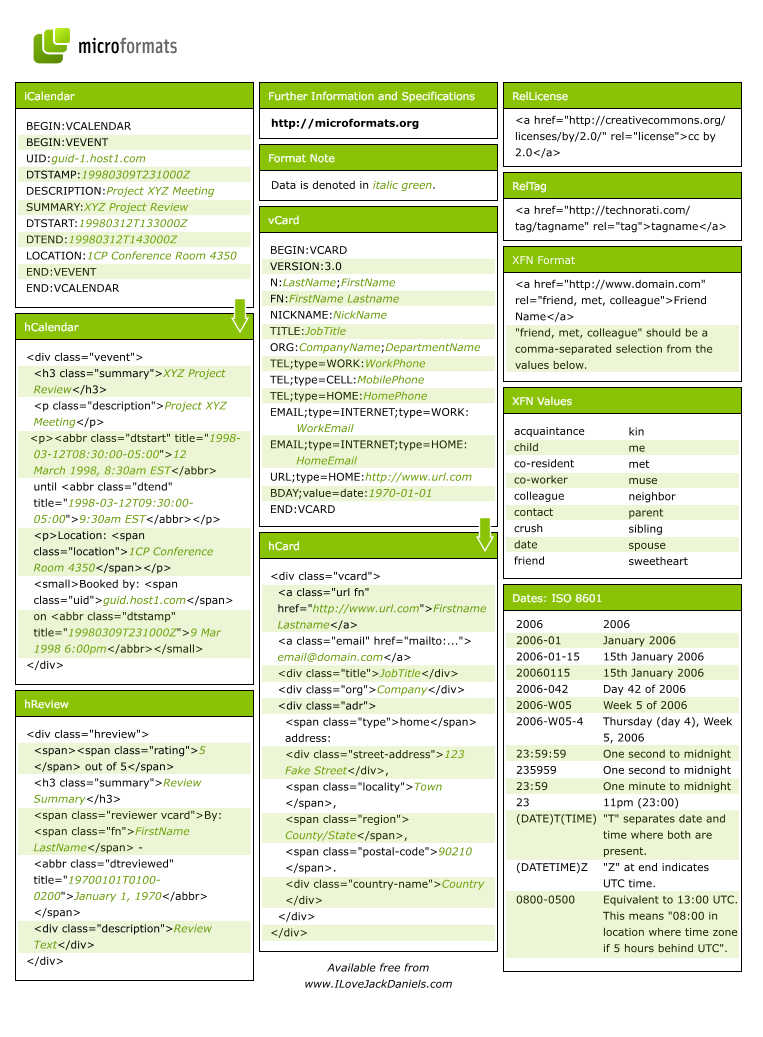
Опять таки, этот способ достаточно удобен, но не покрывает всех вариантов и не сильно часто используется разработчиками (а большинство о них даже не слышало).
Собственно, переходим к HTML5!
Семантические теги в HTML5
Если раньше типовая разметка выглядела таким образом:
<body>
<div id="nav_bar"></div>
<div id="main_header"></div>
<div class="side_bar"></div>
<div id="container">
<div class="section">
<div class="header"></div>
<p>Some Text</p>
<div class="footer"></div>
</div>
<div class="section">
<div class="header"></div>
<p>Some Text</p>
<div class="footer"></div>
</div>
</div>
<div id="main_footer"></div>
</body>
#nav_bar {}
#main_header {}
.side_bar {}
#container {}
.section {}
#header {}
.section p {}
.footer {}
#main_footer
То с появлением HTML5 это бкдет выглядеть таким образом:
<body>
<nav></nav>
<header></header>
<aside></aside>
<div id="container">
<section>
<header></header>
<p>Some Text</p>
<footer></footer>
</section>
<section>
<header></header>
<p>Some Text</p>
<footer></footer>
</section>
</div>
<footer></footer>
</body>
nav {}
header {}
aside {}
section {}
footer {}
section p {}
#container {}
#container header {}
#container footer {}
Новые семантические элементы:
- article – основной контент;
- section – разделение текста на разделы;
- aside - часть контента, который имеет отношение к основному содержанию, но может быть использовано отдельно от него;
- header – шапка веб-страницы;
- footer – подвал веб-страницы;
- hgroup - определяет группу заголовков;
- figure - группирует элементы web-страницы по смыслу;
- menu – секция меню на веб-страницы;
- nav - основные навигационные блоки на странице;
- time – время;
- mark – фрагмент текста, на который следует обратить внимание (strong);
- dialog – диалоги, чаты, итервью.
Схематически это можно показать так:

Вместе с тем некоторые тэги больше не рекомендуют использовать в HTML5 (хотя обратная совместимость есть):
- Acronym
- Applet
- Basefont
- Big
- Center
- Dir
- Font
- Frame
- Frameset
- Noframes
- Strike
- Tt
Профит очевидный – теперь поисковые системы смогут правильно идентифицировать типы контента, что, несомненно, повысит качество поисковой выдачи. Конечно, это все круто, но на этом semantic в HTML5 не заканчивается, а только начинается. Если интересно, то продолжим в следующей статье.