Игрушечная ООСУБД
Предупреждение - сделано на курсовой проект и обладает серьёзными недостатками. Освобождение памяти нужно вызывать через специальный метод и сборщик мусора начинает собирать информацию в этом же потоке и делает это очень медленно. Объекты пишутся в файлы группами и нет логов поэтому надёжность ООСУБД ниже чем у любой коммерческой . И всё же есть и плюсы )))
Теперь могу похвастаться что оно умеет:
var DB = new QueryManager(1, @"Output\md.zip", true, 0.4, @"Output\index.zip", 50, @"Output\imd.zip", 0.0, true);
var firstObjectID = DB.AddObject(new MyClass{ Name = "Hello", Data = "World!" });
var secondObjectID = DB.AddObject(new MyClass{ Name = "Hi", Data = "People!" });
var firstSelectedObject = DB.Select(firstObjectID).Data as MyClass;
var secondSelectedObject = DB.Select(secondObjectID).Data as MyClass;
Console.WriteLine("First object ID: {0}\nSecond object ID: {1}\n", firstObjectID, secondObjectID);
Console.WriteLine("First selected object: {0}", firstSelectedObject.Name + ", " + firstSelectedObject.Data);
Console.WriteLine("Second selected object: {0}", secondSelectedObject.Name + ", " + secondSelectedObject.Data);
DB.Dispose();
var DB2 = new QueryManager(1, @"Output\md.zip", false, 0.4, @"Output\index.zip", 50, @"Output\imd.zip", 0.0, true);
var firstSelectedObject2 = DB2.Select(firstObjectID).Data as MyClass;
var secondSelectedObject2 = DB2.Select(secondObjectID).Data as MyClass;
Говорящая классовая диаграмма (не полная - только то что нужно для использования).
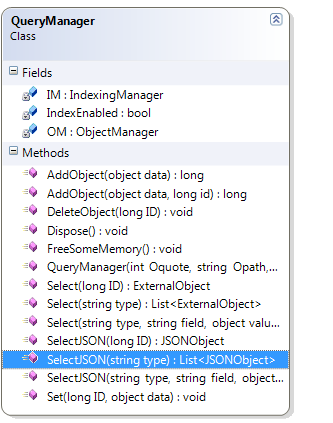
Я был вдохновлён простотой memcached поэтому такое не большое количество запросов. Запросы срабатывают только если хватит оперативной памяти.
Честно говоря пользуюсь данной поделкой для чтения/сохранения структур данных на диск. Весьма удобно благодаря тому что сама ООСУБД использует классный сериализатор Newtonsoft.Json и стандартные для .NET средства архивации. Это позволяет положить на диск любую структуру данных без необходимости предварительно создавать схему данных, при этом это будет сделано порциями по N объектов, а N можно задать.
Предвкушаю вопрос "зачем плодить велосипеды ?" - работа с большими файлами происходит зачастую быстрее и если разработчик догадывается как это можно сделать эффективнее в его приложении то производительность записи можно существенно увеличить (Ценой надёжности естественно).